Building Production-Ready Agents with Amazon Bedrock Agent Core and Knowledge Bases
Marcos Llorens Martinez
April 28, 2026
Table of contents
One of the most important lessons we’ve learned from a decade in the trenches with our customers is simple: your AI agent is only as good as the data it can actually reach.
If your agent can't navigate your internal databases, knowledge repositories, or private documents, it’s just a generic chatbot, and generic doesn't drive business impact.
To move from a "fun pilot" to a production-ready asset, organizations must overcome the real-world hurdles of scaling, security, and identity-aware access.
At the same time, when trying to use their own data, many organizations struggle with:
Scaling from pilot to production
Applying strong security controls and role-based access
Supporting both internal and external users
Scaling from hundreds to thousands of requests per second
Agents may involve long-running tasks that exceed traditional serverless limits
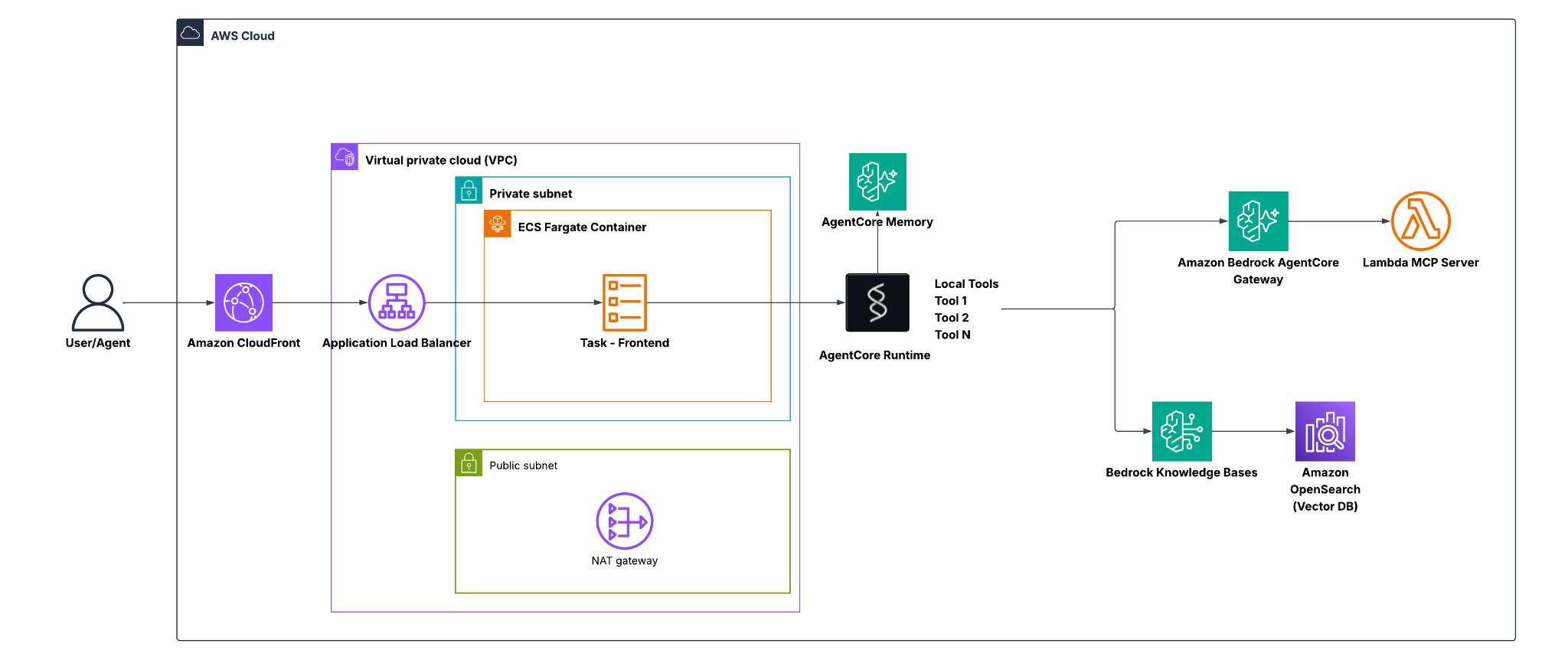
This article walks through the architecture CloudZone uses to help customers deploy enterprise RAG agents that delivers custom responses, scales automatically, and minimizes operational overhead.
The Technical Core
We maximize efficiency and minimize effort by integrating a battle-tested stack designed for the enterprise:
Strands Agents SDK: To build and run sophisticated agents in just a few lines of code.
AWS Bedrock AgentCore Runtime: For secure execution with built-in isolation.
Knowledge Base + OpenSearch Serverless: To capture and ingest your unstructured data for high-performance RAG.
Bedrock AgentCore Gateway + MCP servers for secure tool exposure, centralized policy enforcement and decoupled tool lifecycle management across teams
AgentCore Identity & Memory: To ensure every conversation stays secure, personalized, and grounded in long-term context.
How CloudZone helps customers in the deployment phase
1. Data-first approach
Before anything else, it is important to define what enterprise data the agent should use.
This is what turns a generic assistant into a business assistant.
2. Role-based access for internal and external users
In some scenarios, both internal and external users may use the same platform, with different permissions levels.
Cognito authenticates users
Roles are mapped to allowed policies
Agent tools and data access are filtered by role
With this approach, each user only has access to restricted data sources, following the principle of least privilege.
3. Agent runtime with identity-aware controls
The runtime validates the identity context on every request using claims from the verified JWT token. The agent is exposed as an HTTP service, while AgentCore handles scaling, isolation, and lifecycle management.
AgentCore Identity token exchange
Workload identity mapping per role
Strict fail mode if identity validation is required
4. RAG and memory for real workflows
The solution combines retrieval, tool management, and context continuity. Thanks to a RAG architecture, agents dynamically retrieve context during execution and produce responses grounded in trusted data.
RAG over Bedrock Knowledge Bases (using OpenSearch Serverless as a vector store)
Short-term and long-term memory for better conversations, stronger context continuity across sessions, and more personalized, business-relevant responses over time.
5. Bedrock AgentCore Gateway + MCP servers
With MCP servers it is possible to decouple tools (for example, read operations to databases) from the main agent runtime, which improves security, governance, and scalability: tools can be authenticated, versioned, and managed independently while the agent only accesses the capabilities allowed for each user role.
6. Built for scale from day one
This is not a one-off deployment. It is designed as a long-term platform that can evolve with business demand, user growth, and new AI capabilities without requiring a full redesign. By treating infrastructure, security, and operations as core concerns from the beginning, teams can move faster in production while keeping reliability and governance under control.
Summary
In order to drive real enterprise value from GenAI, you need more than a model endpoint. You need an architecture that connects securely to your business data, enforces identity and role-based access, and scales reliably from pilot to production.
By combining Bedrock Knowledge Bases, OpenSearch Serverless, AgentCore Runtime, AgentCore Gateway, and MCP-based tooling, CloudZone helps organizations move from a generic chatbot to a secure, enterprise-grade RAG agent platform built for long-term growth and adaptability.
At the end of the day, CloudZone helps you move from pilot to production by making sure your AI is secure, scalable, and grounded in the data that matters most.
FAQs
Why is data access so important for chatbot or agent performance?
Because model quality alone is not enough. Business-specific answers require business-specific data.
Can this support both internal and external users?
Yes, with role-based access and identity controls.
How does this help with scaling issues?
The architecture is cloud-native, secure-by-design, and serverless for future growth and scalability needs.
Is this secure for enterprise environments?
Yes, it includes Cognito authentication, AgentCore identity validation, and role-based permissions. So, it is possible to restrict or permit access to different data sources depending on the role of a particular user.
Is it ready for production?
Yes, when deployed with proper governance, monitoring and operational practices, this is a completely valid production ready solution.
More from CloudZone
July 26, 2026
MSP vs. In-House Cloud Operations: How to Build a Shared Cloud Responsibility Model?
Most conversations about MSP vs. in-house cloud operations begin with the wrong question.
Companies ask whether they should manage their cloud internally or hand it over to a managed service provider, as though one side needs to own the entire environment.
MSP
Sergio Gonzaga Santos
July 19, 2026
Claude on AWS: Choosing the Right Deployment Path
Picture the conversation that happens at most software vendors three weeks after someone in engineering quietly starts using Claude inside a feature.
AWS
Vera Barzman
December 14, 2025
10 Best Tools for Cloud Cost Optimization
Let’s face it: Cloud bills can get out of control fast.
FinOps
Thanks for reaching out
We’ve received your request, and one of our experts will be in touch shortly.








.png)
.png)










