
AWS Managed Services vs. Self-Management: Which Is Right for Your Startup?
A practical guide for growing startups navigating cloud operations, FinOps, and compliance in 2026





As organizations increasingly adopt generative AI, most teams discover the cost problem after they've already deployed. Here's how to get ahead of it. Teams working with Google Cloud Vertex AI often discover that without a structured approach, costs can scale quickly and unpredictably.
A well-designed workflow helps organizations balance performance, quality, and cost control from the very beginning. Below is a practical approach to using Vertex AI with optimization in mind.
The process begins with defining the use case and exploring models in Model Garden. This stage is critical not only for selecting the right capabilities, but also for understanding cost implications.
There are a few key pricing principles to keep in mind:
Understanding the pricing unit is essential, as it directly impacts how usage should be monitored and controlled.
Model selection is the most impactful cost decision. Not every use case requires the most advanced model.
A structured evaluation process should include:
This type of “routing” or “waterfall” architecture is one of the most effective ways to control costs at scale.
Pricing varies significantly between models, making comparison essential.
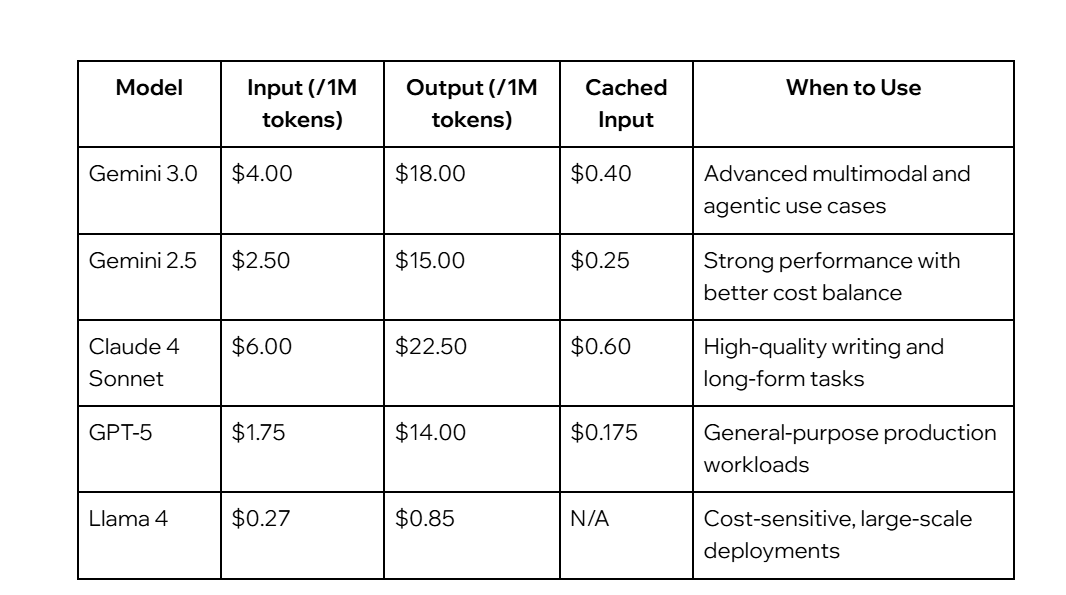
For highly cost-sensitive workloads, lighter models such as Gemini Flash Lite may provide sufficient performance at a significantly lower price point.
After selecting a model, the next step is working in Vertex AI Studio.
This stage focuses on:
Efficient iteration here reduces the risk of costly inefficiencies later in production. Poorly designed prompts or excessive token usage can significantly increase operational costs over time.
Before deploying workloads, optimization becomes essential. At production scale, even small inefficiencies can result in substantial cost increases.
Setting budget alerts is a foundational step. It ensures visibility into usage trends and helps detect anomalies early.
The size of the context window directly affects token consumption. Larger inputs increase costs, so it is important to align context size with actual requirements rather than defaulting to maximum limits.
Many applications generate repeated or similar queries. Prompt caching can reduce redundant processing and lower costs.
Key practices include:
It is important to note that caching primarily reduces input token costs.
For non-production workloads, batching and asynchronous execution can significantly improve cost efficiency. This is particularly useful in testing environments, background jobs, or large-scale data processing tasks.
Beyond Vertex AI, organizations may also consider Gemini Enterprise as part of a broader AI adoption strategy.
Gemini Enterprise integrates AI capabilities into tools such as Gmail, Docs, Sheets, and Meet, while maintaining enterprise-grade security and administrative controls.
It is offered in multiple editions:
Pricing typically starts at approximately $21 per user per month for Business, and $30 per user per month for higher-tier plans.
Optimizing AI usage on GCP requires more than selecting a model and deploying it. It involves a deliberate approach across the entire lifecycle:
Organizations that embed these practices early are better positioned to scale AI workloads sustainably while maintaining financial control.
Vertex AI is Google Cloud’s AI platform that allows organizations to build, test, and deploy AI workloads using models available through Model Garden and Vertex AI Studio.
Without a structured approach, Vertex AI costs can scale quickly and unpredictably, especially as organizations increase their use of generative AI workloads.
Model Garden is the stage where organizations explore and evaluate available AI models based on their use case, capabilities, and pricing considerations.
Model selection is one of the most impactful cost decisions because not every workload requires the most advanced or expensive model.
The article highlights Llama 4 and Gemini Flash Lite as options for highly cost-sensitive workloads.


A practical guide for growing startups navigating cloud operations, FinOps, and compliance in 2026












