The Real Cost of Fine-Tuning: Performance, Risk, and FinOps Reality
Vera Barzman
January 21, 2026
Table of contents
Introduction: Fine-Tuning Strategies on Vertex AI
Model Fine-tuning on Vertex AI offers different strategies, ranging from Supervised Tuning with labeled input-output pairs to Continued Pre-training using raw, unlabeled data.
While fine-tuning can deliver strong performance improvements, it comes with high short-term cost and effort, making it a risky choice initially. In the long term, however, it can become an optimized and scalable solution when used correctly.
Risks of fine-tuning and how to mitigate them
Catastrophic forgetting (loss of existing capabilities):
Fine-tuning does not simply add new knowledge to a model. If done aggressively or on a narrow dataset, it can degrade previously learned patterns, leading to unexpected downstream behavior.
This phenomenon, known as catastrophic forgetting, occurs when a model becomes overly specialized for a new task and loses its general capabilities. This risk is often amplified when the model is optimized too aggressively on a limited dataset, leading to overfitting rather than true learning.
To reduce this risk:
Use high-quality, well-labeled datasets that are representative of your target use case.
Ensure sufficient training volume, typically hundreds to thousands of examples, depending on task complexity and tuning method.
Enable checkpoints during Vertex AI / Gemini model tuning.
Checkpoints act as snapshots of the model state during training. They allow you to save tuning progress, compare intermediate model performance, and select the best-performing checkpoint before overfitting occurs.
High initial costs and engineering effort:
Full fine-tuning requires substantial computational resources for both training and serving, leading to higher short-term costs and increased engineering effort. This makes fine-tuning a more substantial investment than prompting or lightweight adaptation techniques.
Infrastructure choice plays a major role here. In some Vertex AI workloads, TPU v3 Pods (64 cores) can offer better price-to-performance compared to A100 GPUs, particularly for large-scale training. However, this advantage depends on workload compatibility and GCP-native pipelines.
A more cost-efficient alternative is parameter-efficient tuning (PET). Instead of updating all model weights, PET techniques adapt only a small subset of parameters. This approach:
Enables flexible multi-task adaptation without retraining the full model.
For many production use cases, parameter-efficient tuning provides a strong balance between performance, cost, and operational complexity.
Fine-tuning vs. RAG
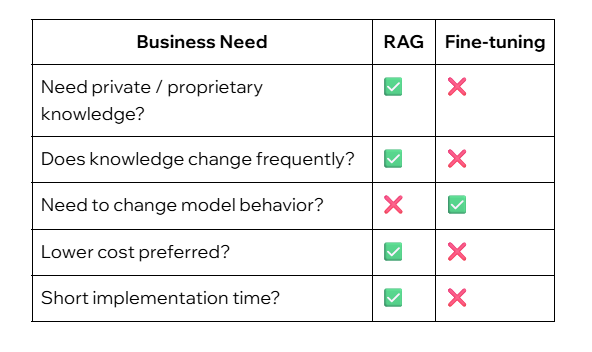
RAG (Retrieval-Augmented Generation) is a technique that enhances large language models by retrieving relevant external information during inference. One of the key limitations of LLMs is that they lack access to private or proprietary organizational data, which can lead to incomplete or hallucinated responses.
With Vertex AI RAG Engine, the model’s context is dynamically enriched with data from external sources, such as internal documents, databases, or knowledge bases. This allows the model to ground its responses in up-to-date, organization-specific information, improving accuracy and reducing hallucinations without modifying the model’s underlying weights.
Unlike fine-tuning, RAG does not alter the model’s learned representations. Instead of embedding knowledge directly into the model, relevant information is retrieved and injected into the prompt at query time. This makes RAG particularly effective when:
The data changes frequently.
The knowledge base is large or continuously growing.
You want faster iteration with lower training costs.
You need explainability and traceability of answers.
In contrast, fine-tuning is better suited for adapting a model’s behavior, style, or task-specific reasoning, rather than teaching it new factual knowledge. In many real-world Vertex AI deployments, RAG is often the preferred first step, with fine-tuning reserved for cases where consistent behavioral changes are required.
When to use which approach
Conclusion: Start Smart, Fine-Tune When Necessary
Fine-tuning is a powerful tool, but it is not a silver bullet. While it delivers consistent performance for specific tasks, the upfront investment in compute and engineering effort is significant. To avoid the risks of overfitting and high costs, the most effective strategy is often to proceed incrementally: start with RAG to manage your knowledge base, and reserve fine-tuning for when you need to fundamentally reshape model behavior or style.
Cloud Cost Optimization: How to reduce spend in 2026
Between 28% and 50% of cloud spend goes to waste. Not because organizations are careless - but because cloud computing makes it incredibly easy to provision resources instantly, without the governance structures needed to keep cloud costs in check.
FinOps
Vera Barzman
December 14, 2025
10 Best Tools for Cloud Cost Optimization
Let’s face it: Cloud bills can get out of control fast.
FinOps
February 16, 2026
Generative AI on Google Cloud- An Introduction
Generative AI has rapidly moved from a buzzword to a production reality. What started as experimental chatbots is now powering critical workloads, automating support, accelerating software development, and reshaping how products are built on Google Cloud.
Google Cloud
Thanks for reaching out
We’ve received your request, and one of our experts will be in touch shortly.






.png)













