
Building Production-Safe AI Support Agents: Architecture, Safety Guardrails & Real-World Implementation
The engineering behind an autonomous agent that investigates AWS incidents and the guardrails that make it safe to put in front of production.





In Part 1 of this series, we explored why Amazon Bedrock is the engine for enterprise AI and identified the hidden cost drivers, like prompt inflation and retrieval overload, that can derail your budget. Now, we turn to the solution: how do you balance high-performance innovation with strict financial discipline? Here is a FinOps-driven strategy for optimizing Amazon Bedrock.
AWS has published Bedrock cost optimization guidance here: https://aws.amazon.com/bedrock/cost-optimization/
Running Bedrock efficiently requires balancing cost, performance, and accuracy. The following strategies help enterprises maintain that balance as usage scales.
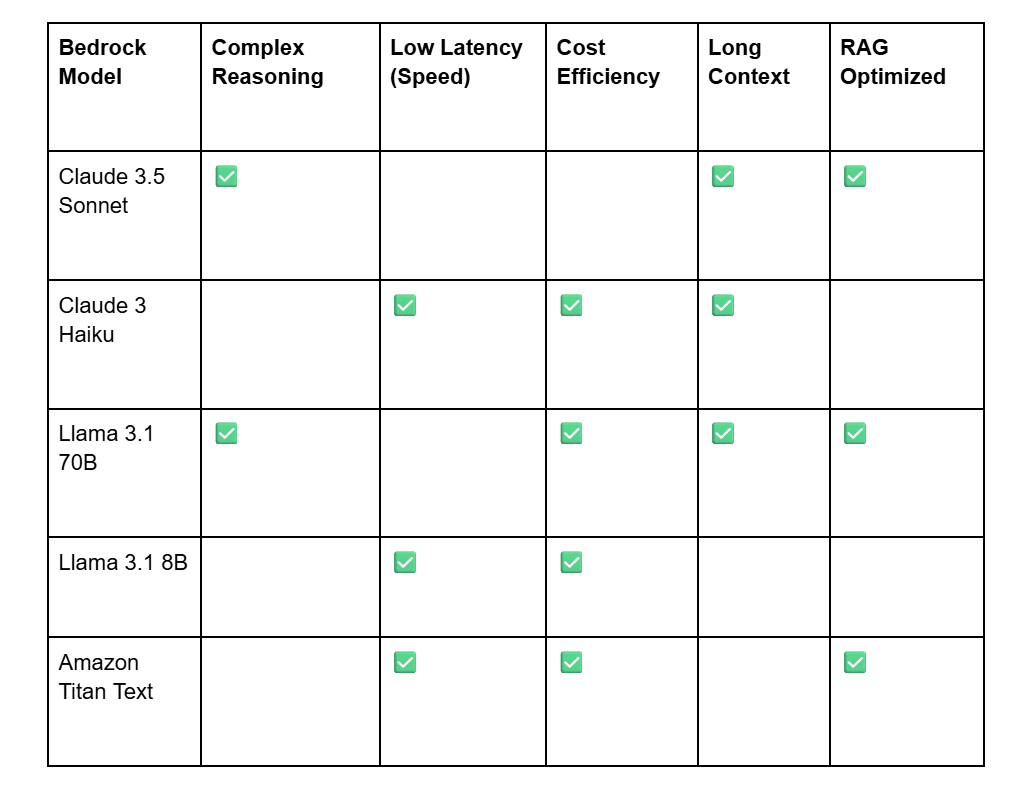
Right-sizing the model is the single most impactful FinOps decision. Large-capacity models deliver stronger reasoning, but many enterprise tasks (classification, summarization, routing, extraction) can be handled by lighter, more cost-efficient options such as Amazon Titan or smaller Llama variants.
Another way to reduce model costs without compromising capability is Amazon Bedrock Model Distillation. This is when a smaller “student” model is trained using high-quality outputs from a larger “teacher” model. In practice, you can use a powerful model like Claude 3.5 Sonnet (teacher) to generate high-quality training data, then use that data to train a smaller model like Llama 3 8B (student). The result is a smaller, cheaper model that can perform a specific task with near-expert accuracy.
AWS reports distilled models can be up to 500% faster, up to 75% less expensive, and deliver under 2% accuracy loss for tasks like RAG. Evaluating models systematically using Bedrock’s evaluation tools helps teams balance accuracy, latency, and cost together, not in isolation.
Key takeaway: Don’t default to the biggest model. Use the smallest model that can do the job, or “teach” a small model to act like a big one for a fraction of the price.
Prompt design reduces cost by reducing input tokens, often without compromising response quality. High-impact techniques include:
One of the most powerful optimization features is Prompt Caching. AWS reports prompt caching can deliver up to a 90% reduction in cost and up to an 85% improvement in latency. This is especially effective for repeated system prompts, compliance templates, FAQ patterns, or RAG prefix sequences.
RAG improves grounded accuracy, but it is also one of the most common hidden sources of overspending. Inefficiencies typically come from:
RAG becomes cost-efficient only when retrieval is precise. Clean, minimal retrieval improves both accuracy and cost.
Many enterprise workloads repeatedly use the same system prompts, boilerplate text, or frequently asked questions. Caching, both via Prompt Caching and at the application layer, can dramatically reduce token usage. Additional caching layers in Amazon API Gateway or DynamoDB can reduce Bedrock calls even further.
To optimize this, think of caching in two layers:
1. Input Caching (Amazon Bedrock Prompt Caching)
This optimizes the context you send to the model. You are charged at a reduced rate for tokens read from cache, and cache write pricing varies by model. The value appears when prompts reuse large, repeated prefixes.
2. Output Caching (API Gateway and DynamoDB)
This optimizes the responses so you do not have to call Bedrock at all.

Prompt caching is especially effective for repeated prefixes in RAG workflows, policy or compliance-based responses, chain-of-thought templates, and long system instructions.
Provisioned Throughput delivers predictable performance at lower unit cost for stable workloads. It becomes cost-efficient when traffic is consistent throughout the day, latency requirements are strict, the workload requires steady concurrency, and model calls per second can be forecast reliably. Right-sizing Model Units (MUs) is critical to avoid underutilization or latency degradation.
Successful FinOps requires continuous visibility. Services like AWS CloudWatch, AWS Cost Explorer, and Bedrock usage reports help identify issues. Organizations should monitor metrics like:
Bedrock Agents enable applications to orchestrate workflows, often triggering multiple model calls in a single request. Without design discipline, this can multiply token usage. Advanced architectures, including cascaded models or routing systems, help mitigate this. A lightweight router model can handle the majority of simple tasks efficiently, passing only complex requests to a larger model. According to AWS, intelligent prompt routing can reduce cost by up to 30% without accuracy loss.
By combining these techniques, organizations can operate Bedrock with financial clarity as usage scales. Bedrock provides a governed, flexible platform for deploying AI at scale, but cost optimization remains an ongoing discipline.
Organizations that succeed with Bedrock tend to:
Amazon Bedrock is most powerful when paired with a mature FinOps practice that aligns innovation with cost governance. To help you build this sustainable framework, we invite you to explore our FinOps page for further guidance on best practices.


The engineering behind an autonomous agent that investigates AWS incidents and the guardrails that make it safe to put in front of production.





.png)






