
Building Production-Safe AI Support Agents: Architecture, Safety Guardrails & Real-World Implementation
The engineering behind an autonomous agent that investigates AWS incidents and the guardrails that make it safe to put in front of production.





Artificial intelligence has rapidly evolved from experimentation to enterprise-wide adoption. As generative AI becomes integral to products and workflows, the priority shifts from simple deployment to operational efficiency. Amazon Bedrock supports this by offering a fully managed, unified API for leading foundation models, removing infrastructure complexity. However, scaling successfully requires more than access, it demands a robust FinOps strategy to balance performance with cost.
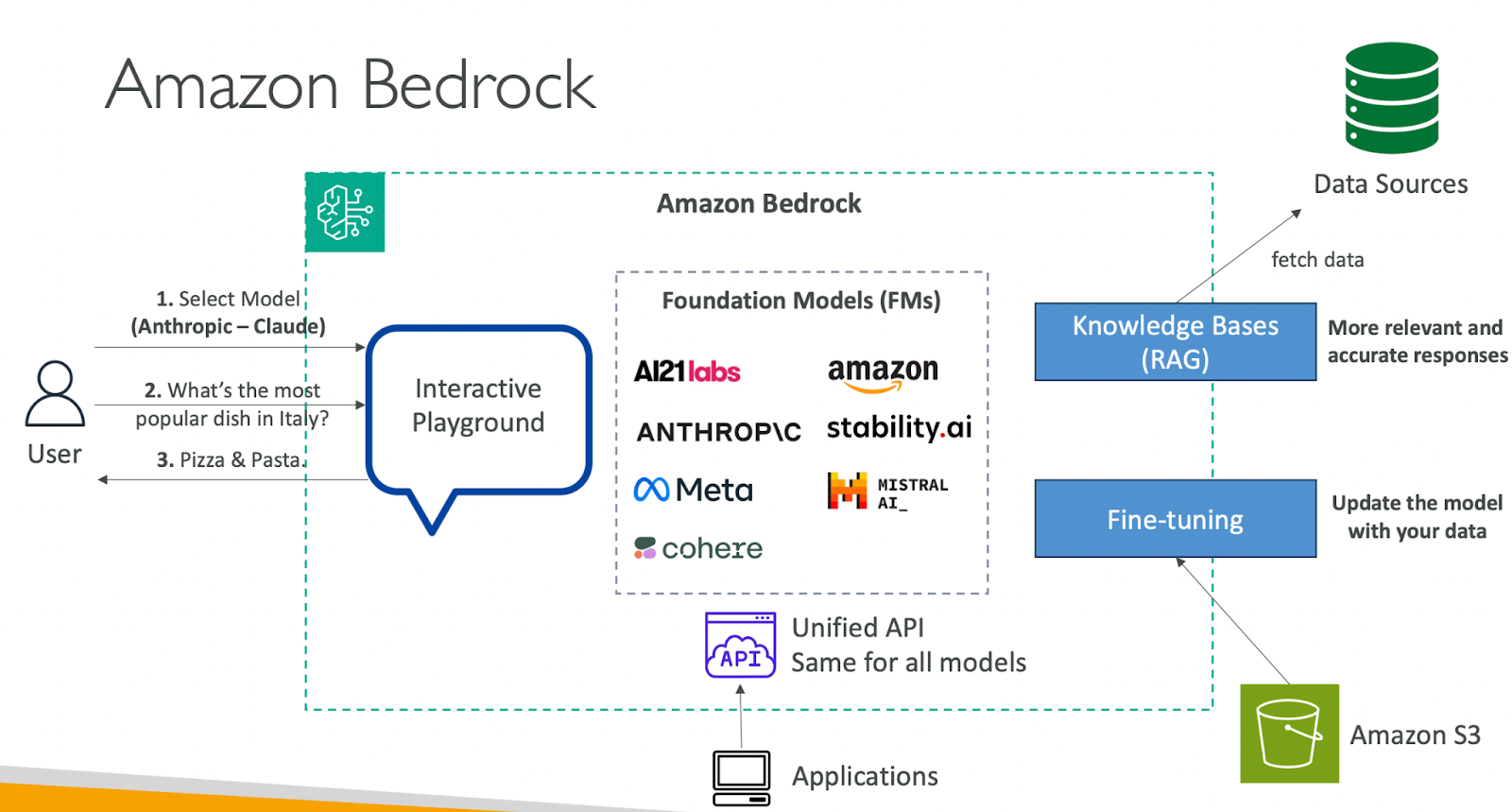
Amazon Bedrock was designed for organizations that want AI adoption to be secure, repeatable, and production-ready, not dependent on experimental pipelines or ad-hoc integrations. Bedrock offers access to multiple foundation models under one umbrella, allowing enterprises to evaluate, switch, or combine models based on cost, performance, and use case fit.
Available models include:
This model diversity lets teams avoid being tied to a single model and match each workload to the most cost-effective option. For FinOps teams, this flexibility matters because each model introduces distinct pricing, latency, context window, and scaling characteristics.

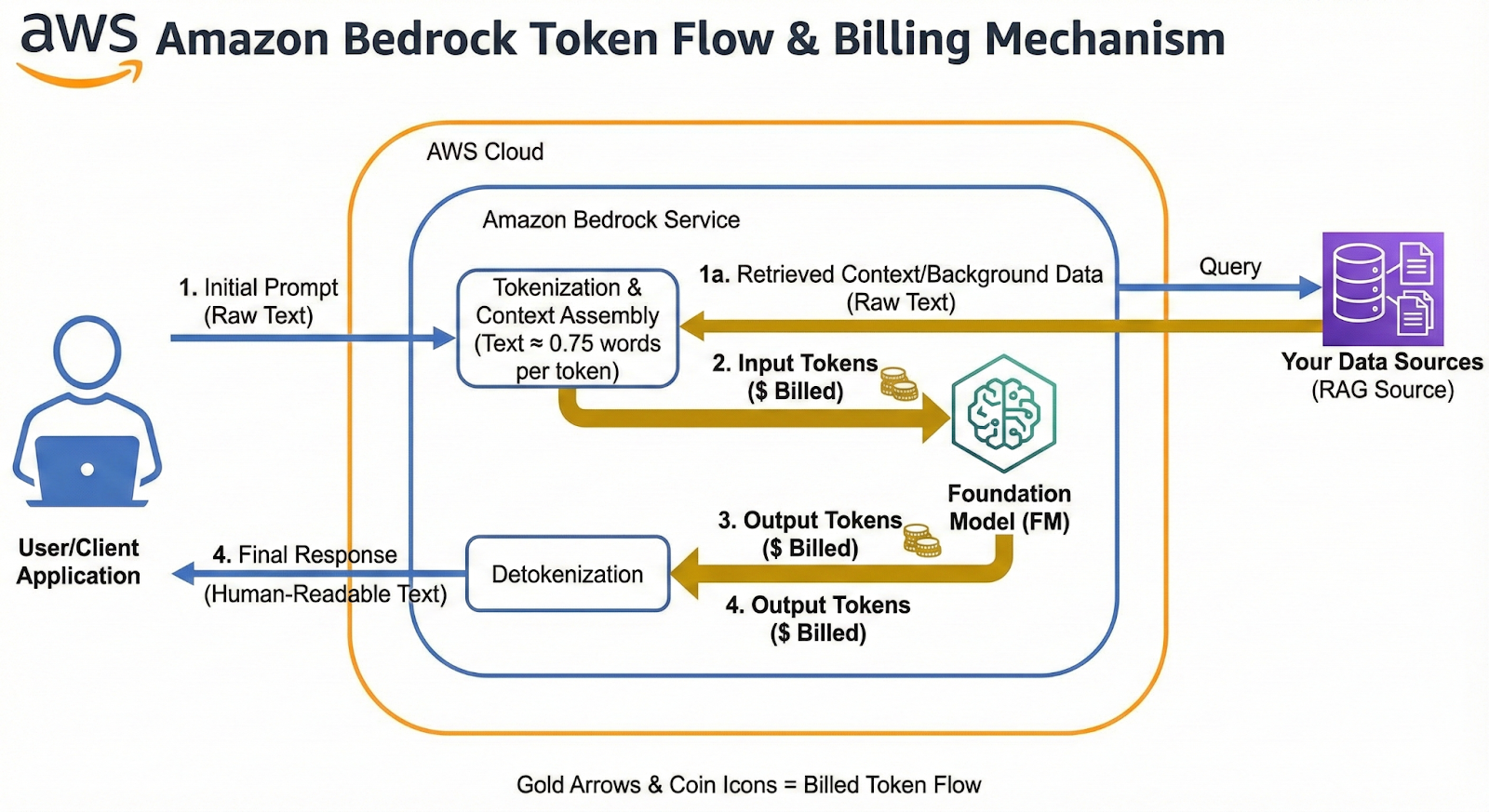
To operate Bedrock effectively, teams must understand how AWS calculates cost by the token, not by the word.
Think of a token as a small chunk of text, typically a few characters. For example, a simple word like “cloud” is often 1 token, while a longer word like “implementation” may be split into multiple tokens.
Bedrock bills for two things:
Since different models carry different token prices, and input and output pricing can vary significantly, small changes in prompt design, retrieval behavior, or output length can compound into major cost shifts.
Common drivers of unexpected spend include:
Once the mechanics of token billing become clear, the reasons behind overspending and the opportunities to reduce it become much easier to identify.
Across industries, Bedrock overspending tends to appear in predictable patterns:
These patterns create meaningful cost challenges, but they also represent straightforward opportunities for improvement.
In Part 2 of this series, we will dive into specific strategies, from model distillation to caching architectures, that turn these challenges into a competitive advantage.


The engineering behind an autonomous agent that investigates AWS incidents and the guardrails that make it safe to put in front of production.





.png)






